
Expanded DBTagger: Keyword Mapping for Linking Text to Database
Jan 16, 2024
In collaboration with Ekrem Polat, our research extends the work initiated by DBTagger, an instrument that performs keyword mapping—a bottleneck step in the text-to-SQL translation for natural language queries. DBTagger relies on the labor-intensive process of manually annotating extensive data. To address this challenge, we present a novel system that incorporates weak supervision, significantly reducing the need for manual annotation. Our method leverages existing annotated data from DBTagger and extends it to a broader range of database schemas, including those in the comprehensive Spider benchmark. Additionally, we fine-tuned pre-trained models like BERT and T5 to enhance the system's ability to map keywords more effectively. This expanded dataset and improved methodology enables query interpretation across diverse domains without extensive manual labeling. Navigate to the GitHub repository to view the code by clicking here.
In the field of database management, the translation of Natural Language Queries (NLQs) to Structured Query Language (SQL) represents a significant challenge, particularly in the context of keyword mapping. Keyword mapping is the complicated process of creating relations between the tokens found in a user's query and the corresponding elements within a relational database—such as tables, attributes, and values. This task is not only matching strings of natural language tokes but rather understanding the intent behind each token and accurately linking it to a database entity that holds the relevant data. The complexity of this problem lies in the diverse ways in which a user might phrase a query and the complex structure of databases that often include multiple relationships and constraints.
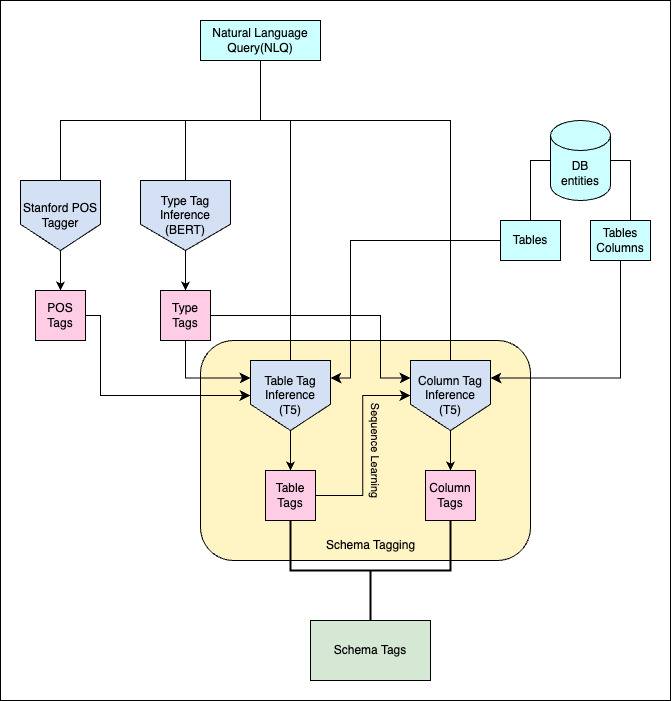
The task of keyword mapping within the scope of translation of Natural Language Queries (NLQs) into Structured Query Language (SQL) queries is methodically approached as a three-step process in our system.
The initial step is POS(Part-of-Speech) Tagging. This involves tagging each word with its part of speech, like whether it's a noun or a verb. We utilize the robust Stanford CoreNLP toolkit to ascertain the grammatical constituents of the words in the queries.
The second step is Type Tagging. It is used to determine the connection between the elements of the database, such as tables, attributes, or values, and natural language tokens. The process involves categorizing the words under seven distinct type tags: TABLE, TABLEREF, ATTR, ATTRREF, VALUE, COND, and O (OTHER). These type tags will be utilized for predicting schema tags.
The third step is Schema Tagging. At this step, the prediction of specific schema tags, which directly correspond to the actual names of tables or attributes within the database for each token, is performed. The schema tag is what truly defines the precise database element the keyword is indicating.
POS(Part-of-Speech) Tag Extraction
We extracted the POS tags from the Spider dataset using the Stanza library from Stanford CoreNLP. These tags are the foundation for schema tag prediction and play an essential role in understanding the structure of natural language queries. An example for POS tagging is given below.
| NL Tokens | How | many | heads | of | the | departments | are | older | than | 56 | ? |
|---|---|---|---|---|---|---|---|---|---|---|---|
| POS Tags | WRB | JJ | NNS | IN | DT | NNS | WBP | JJR | IN | CD | - |
Type Tag Extraction
We employed weak supervision to extract type tags across different database schemas. With a dataset of 1172 training queries and a mix of various domains (IMDb, Scholar, Yelp, etc.), we fine-tuned both the BERT and T5 models. The BERT model outperformed the T5 model with a test accuracy of 99.7%, marking it as the most reliable for type tag prediction. These type tags will be critical in schema tag prediction, acting as indicators for linking tokens to their respective database elements.
For input serialization, we prepared the input by combining the natural language query with the tables and columns from the corresponding database. Special tokens [T] and [C] were added to the token vocabulary to refer to the table and column. The serialized input (X) is constructed as follows:
X = [CLS], q₁, q₂, ..., qᵢ, [T], t₁, [C], c₁₁, c₁₂, ..., c₁ₖ, [T], t₂, [C], c₂₁, c₂₂, ..., c₂ₙ, ..., [T], tₘ, [C], cₘ₁, cₘ₂, ..., cₘₚ, [SEP]
In this equation, q₁, q₂,...qᵢ represent the tokens from the natural language query, and t₁, t₂,...tₘ are the table names from the database schema. The columns corresponding to these tables are represented by c₁₁, c₁₂,...cₘₚ, where the first subscript denotes the associated table and the second subscript indicates the specific column within that table. Special tokens [T] and [C] are used to signify table names and column names respectively.
This serialization method allowed the model to understand the relationship between the tokens in the query and the database tables/columns, improving the accuracy of type tag prediction significantly.
Schema Tag Extraction
Schema tags are defined as table and column pairs (e.g., movie.release year) as shown in the example below. The schema tag prediction task cannot be considered as a simple classification task like in the type tag prediction because the application designed to work on the cross-domain schema/databases which means that there are various database table names and column names. So, the number of possible predictions is not bounded. In light of these factors, we consider this task as a text-to-text translation task and decided to utilize T5, which is a pre-trained encoder-decoder model. However, due to the task's complexity, we split the extraction into two sub-tasks: table tagging and column tagging, which helped simplify the model's prediction task and improve overall accuracy.
| Natural Language Token | Type Tag | Schema Tag |
|---|---|---|
| What | O | O |
| year | ATTR | movie.release_year |
| is | O | O |
| the | O | O |
| movie | TABLE | movie |
| Dead | VALUE | movie.title |
| Poets | VALUE | movie.title |
| Society | VALUE | movie.title |
| from | O | O |
| ? | O | O |
Table Prediction - Schema Tag Extraction
The first sub-task of schema tagging is table prediction. In this task, the goal is to identify which table(s) from the database schema are referenced by the tokens in the natural language query. Tokens such as TABLE, TABLEREF, ATTR, ATTRREF, and VALUE are often linked to a specific table in the database. To ensure accurate predictions, we leverage a fine-tuned T5-base model.
The table prediction process begins by serializing the natural language query, type tags, and part-of-speech (POS) tags together. This serialization allows the model to understand the relationship between query tokens and the corresponding tables in the database. The model is then tasked with predicting which table each token corresponds to based on this serialized input.
For instance, consider the query "What year is the movie Dead Poets Society from?". In this query, tokens like "movie" are strongly tied to the database table movie. The fine-tuned T5-base model effectively captures these relationships through the serialization process, enabling it to accurately predict the relevant table.
Through experimentation, we tested various serialization techniques and found that concatenating the natural language tokens with their corresponding type and POS tags provided the best results. This approach achieved a 91% accuracy in table prediction on our test set.
The serialization technique used for table tagging is structured as follows:
X = [CLS], q₁, q₂, ..., qᵢ, [TTAG], ttag₁, ttag₂, ..., ttagᵢ, [POS], p₁, p₂, ..., pᵢ, [T], tname₁, tname₂, ..., tnameₙ, [SEP]
In this equation, q₁, q₂,...qᵢ represent the tokens from the natural language query, ttag₁, ttag₂,...ttagᵢ are the corresponding type tags, and p₁, p₂,...pᵢ are the POS tags. The table names tname₁, tname₂,...tnameₙ represent the possible tables in the database schema that are relevant to the query. By utilizing this structured input, the model is able to accurately predict the correct table(s) for each query token.
Column Prediction - Schema Tag Extraction
The second sub-task in schema tagging is column prediction, which is more complex than table prediction due to the higher number of columns in a database. Column prediction focuses on tokens that are likely to correspond to database columns, such as tokens tagged as VALUE, ATTR or ATTRREF. This step builds on the results of table prediction and identifies the specific columns relevant to the tokens in the natural language query.
To achieve this, we fine-tuned the T5-small model, which leverages its contextualization ability to learn the relationships between tokens in the query and the database columns. The model predicts the appropriate column names for each token, with sequence learning applied to maintain coherence across the entire query.
The input for this task is serialized by concatenating the natural language query tokens with their type tags and the relevant columns from the tables predicted in the earlier step. Only columns related to the predicted table are included in the input to improve prediction accuracy and reduce unnecessary complexity. POS tags are excluded for this sub-task since they are utilized in table prediction part. The serialization for the column prediction task can be written as:
X = [CLS], q₁, q₂, ..., qᵢ, [TTAG], ttag₁, ttag₂, ..., ttagᵢ, [SEP], c₁, c₂, ..., cₘ [SEP]
Here, the natural language tokens (q₁, q₂,...qᵢ) are combined with the type tags (ttag₁, ttag₂,...ttagᵢ), and the columns (c₁, c₂,...cₘ) predicted from the relevant tables. This structured input allows the model to capture the relationship between query tokens and the appropriate columns within the database, resulting in a column prediction accuracy of 82%.
Synthetically Generating Keyword Mapping Data for Spider
The core of our research lies in synthetically generating keyword mapping data, especially when faced with the challenge of a limited labeled dataset. We applied our model to the Spider dataset, which contains 8,659 natural language queries across various domains. However, due to the manual effort required for data annotation, our labeled dataset initially only comprised 1,172 queries. To address this gap, we expanded the Spider dataset by generating synthetic keyword mapping data, allowing the model to learn across diverse database schemas.
Our fine-tuned models, starting with T5-base for table prediction, utilized the serialized input data to predict the relevant tables for each query. We serialized the natural language queries by incorporating POS tags and type tags to enrich the model's contextual understanding. After the table prediction, the fine-tuned T5-small model was employed for column prediction. In this step, inputs were similarly serialized, and the predicted columns were stored.
The Spider dataset, however, does not include direct schema tagging labels, making conventional evaluation methods challenging. We addressed this by using an SQL parser library to extract tables and columns from the SQL queries corresponding to each natural language query. The predicted schema tags were then compared against those extracted from the parsed SQL queries. Accuracy was calculated by comparing the number of correct classifications to the total number of possible classifications in both the predicted and extracted schema tags. The overall schema tagging accuracy for the Spider dataset was 20.2%, with table prediction achieving an accuracy of 40.8%.
Limitations
While our system showed promise in improving keyword mapping performance for text-to-SQL tasks, several limitations were encountered that impacted overall accuracy. First and foremost, the size of the labeled dataset presented a major challenge. The dataset (including train, dev and test sets) used for model training and performance evaluation contains only 1,172 queries, that is significantly smaller than the Spider dataset, which includes 8,659 queries. This disparity limited the model's exposure to a wide range of query structures, reducing its ability to generalize effectively across unseen data. The manual annotation process, performed by students, also introduced potential inaccuracies in labeling, which may have affected the quality of the training data.
Another critical limitation stems from the multi-step process required for schema tag prediction. The task is inherently complex, involving several stages, including POS tagging, type tagging, table prediction, and column prediction. An error in any of these stages propagates to the subsequent steps, reducing the overall accuracy. For instance, incorrect table predictions result in misaligned serialized inputs for column prediction, leading to further inaccuracies in the final schema tags.
Additionally, the evaluation method itself posed challenges. The Spider dataset includes many complex SQL queries, often involving join operations that reference column IDs and primary keys. Extracting and annotating these IDs from natural language queries proved difficult, and SQL queries with join conditions were particularly hard to handle.
Moreover, the pre-trained T5 models introduced their own set of challenges. In text-to-text transformation tasks, a mismatch between input and output token numbers often caused misalignment problems, particularly in table and column predictions. Extra tokens generated by the model further degraded performance, particularly in cases involving well-known entities or proper nouns, where the model struggled to correctly identify the relevant database tables.
These challenges highlight the need for more sophisticated methods to handle complex queries, larger training datasets, and better alignment between input and output tokens in pre-trained models. Despite these limitations, the work lays the foundation for future enhancements in text-to-SQL keyword mapping systems.
You might also be interested in reading this: A Cloud-Native Application: GelGit Travel
Hasan Alp Caferoglu © 2024