
Image Segmentation with R2U-Net
Jun 11, 2024
In this project, addressing semantic segmentation task in computer vision, the Recurrent Residual Convolutional Neural Network, which is a modified version of U-Net called R2U-Net, is implemented using a Oxford-IIIT Pet dataset not used in the reference paper. You can view the code by navigating to the GitHub repository by clicking here.
Image segmentation, a crucial task in computer vision, is essential in various practical applications like autonomous driving and medical image analysis. The task involves partitioning an image into multiple semantically meaningful regions. Over the years, deep learning techniques, particularly convolutional neural networks (CNNs), have revolutionized image segmentation, yielding remarkable results in terms of accuracy and efficiency.
One popular architecture that has gained significant attention in recent years is U-Net with encoder-decoder architecture. R2U-Net incorporates recurrent, residual convolutional layers into the U-Net architecture, which aims to enhance the model's capability to learn robust feature representations.
Dataset
The dataset used in the project is ”The Oxford-IIIT Pet Dataset,” published by the University of Oxford Visual Geometry Group. It consists of 37 classes of both dog and cat species - each class having approximately two hundred images. Namely, there are 12 cat breeds and 25 dog breeds, each having 2371 and 4978 images, respectively. Original images in the dataset are in various sizes. In order to feed the images to the neural network, they were rescaled to 256 x 256 for the implementation. The ground truth of the images in the dataset is segmented as the background, foreground, and border of the animals, as seen in Figure 1. In the project the ground truth images changed by pixel mapping such that the border of the animals were labeled as part of the animal. Put simply, the network doesn't provide the outline of the animal. After pixel mapping, ground truth images contained thin curves that came from the border of the animals. In order to eliminate these thin curves, closing morphological operation was applied as seen in Fig 2.
Figure 1: Samples from the Oxford-III dataset
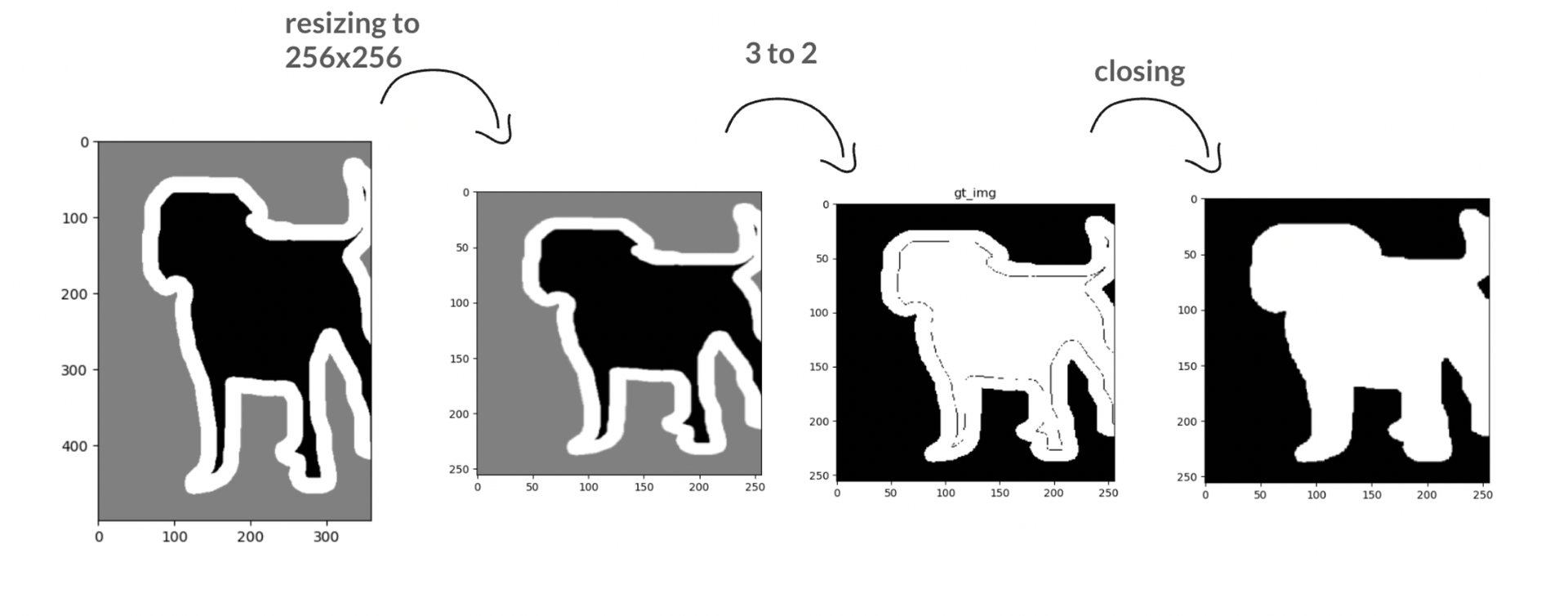
Figure 2: Data pre-processing operation representation
Architecture
R2U-Net can be described as recurrent convolution layers with residual connectivity added to well known U-Net architecture. The overall model and its component structures are provided in Figure 3. This model includes the convolutional encoding and decoding units identical to U-Net's. The R2U-Net model differs from the U-Net approach consisting of regular forward convolutionals by the recurrent convolutional layers with residual units which will be explained briefly. Utilizing these recurrent convolutional layers with residual units improves the feature representation, which is specially designed for image segmentation.
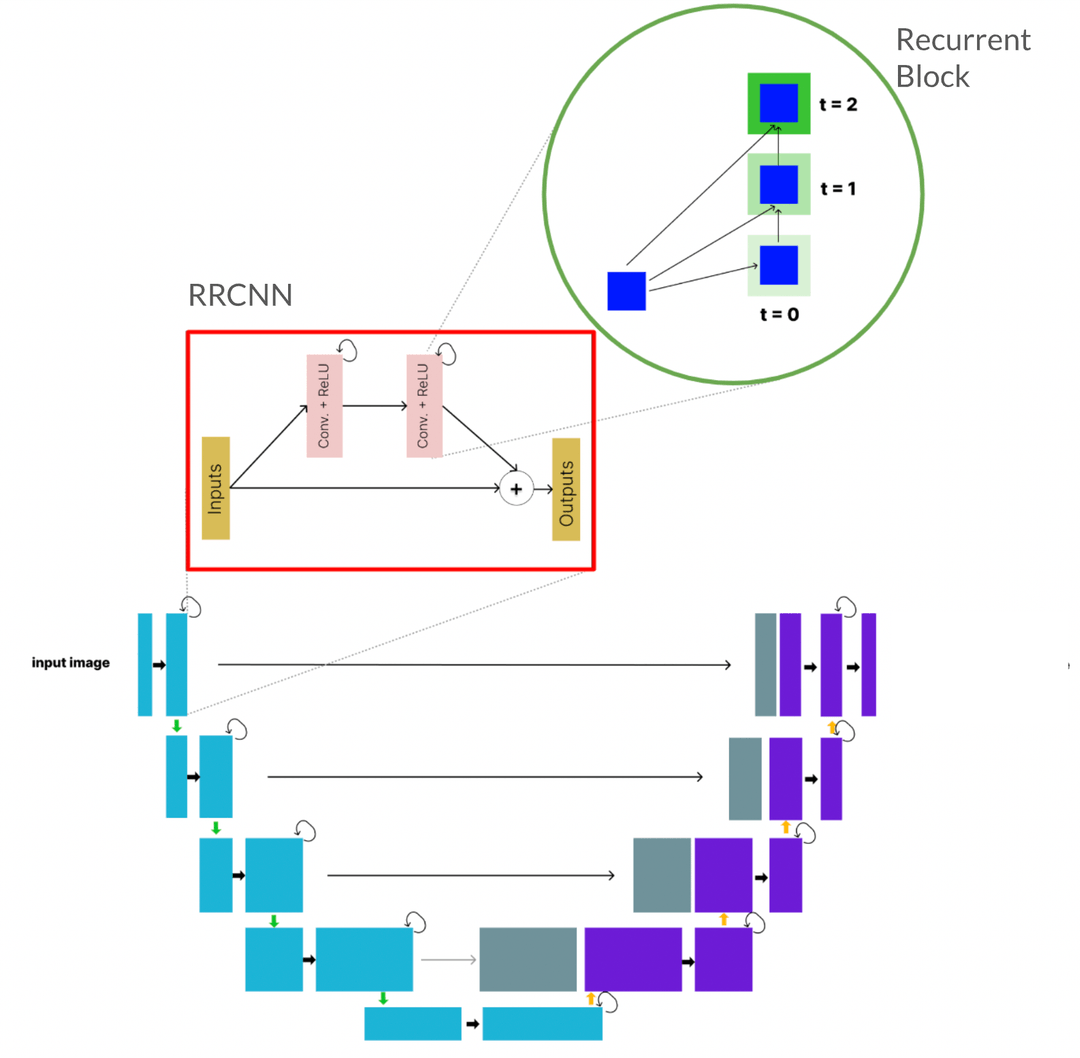
Figure 3: R2U-Net Architecture consisting of RRCNN and Recurrent Blocks
The unfolded recurrent block, which constitutes the base component of the RRCNN block and hence the R2U-Net architecture, with different time steps (t=2 and t=3), is demon- strated in Figure 4. As the parameter t (time step) increases, the number of iterations and the running time increases accord- ingly.
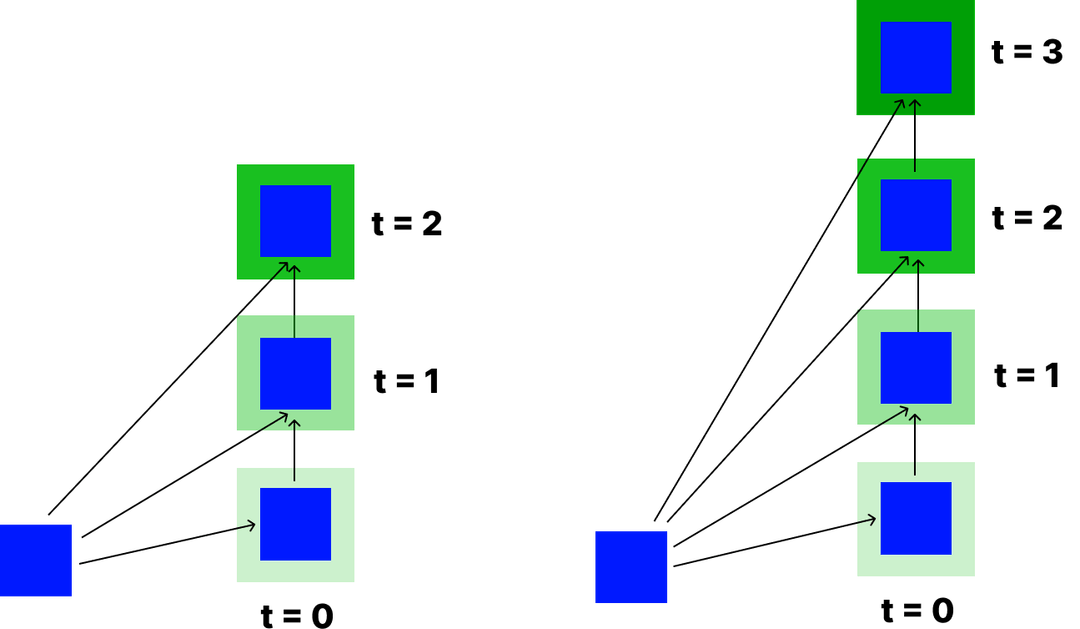
Figure 4: Recurrent block structure for t=2 and t=3
Experiments and Results
Comprehensive experiments for model evaluation were conducted using the hyperparameters batch size, number of epochs, learning rate, time step (t), and learning rate decay. The dataset percentages that were used in these experiments are provided in Table 1. Experiments are conducted on both normal and large R2U-Net architecture where large stands for the increase in the channel sizes through the network. The results obtained for both normal and smaller networks are provided in Table 3 and Table 4, respectively. The former represents the results using the structure and the channel sizes provided in the first row of Table 2. The latter represents the results using the channel sizes provided in the second row of the Table 2. Note that even the R2U-Net model, not the large one, differs from the original paper by one additional convolutional step. The differentiation of the number of learnable parameters according to the channel size structures can be inferred from the table. During the experiments Adam optimizer is used as optimizer with the paraters of and .
| Set | Train (60%) | Validation (20%) | Test (20%) |
|---|---|---|---|
| Image number | 4437 | 1458 | 1458 |
| Model | Network Architecture Channel Sizes | t (Time Step in Recurrent Blocks) | Number of Parameters |
|---|---|---|---|
| R2U-Net | 3 → 16 → 32 → 64 → 128 → 256 → 128 → 64 → 32 → 16 → 1 | 2 | 2.4 Million |
| R2U-Net Large | 3 → 64 → 128 → 256 → 512 → 1024 → 512 → 256 → 128 → 64 → 1 | 2 | 39 Million |
As the evaluation metrics, we utilized the Dice coefficient and Jaccard index, also known as IoU (intersection over union), since these are two of the most used evaluation metrics for image segmentation tasks.
Dice Coefficient:
Intersection over Union (Jaccard Similarity):
where and are the ground truth and the segmented results, respectively.
Table 3: Experimets for the R2U-Net.
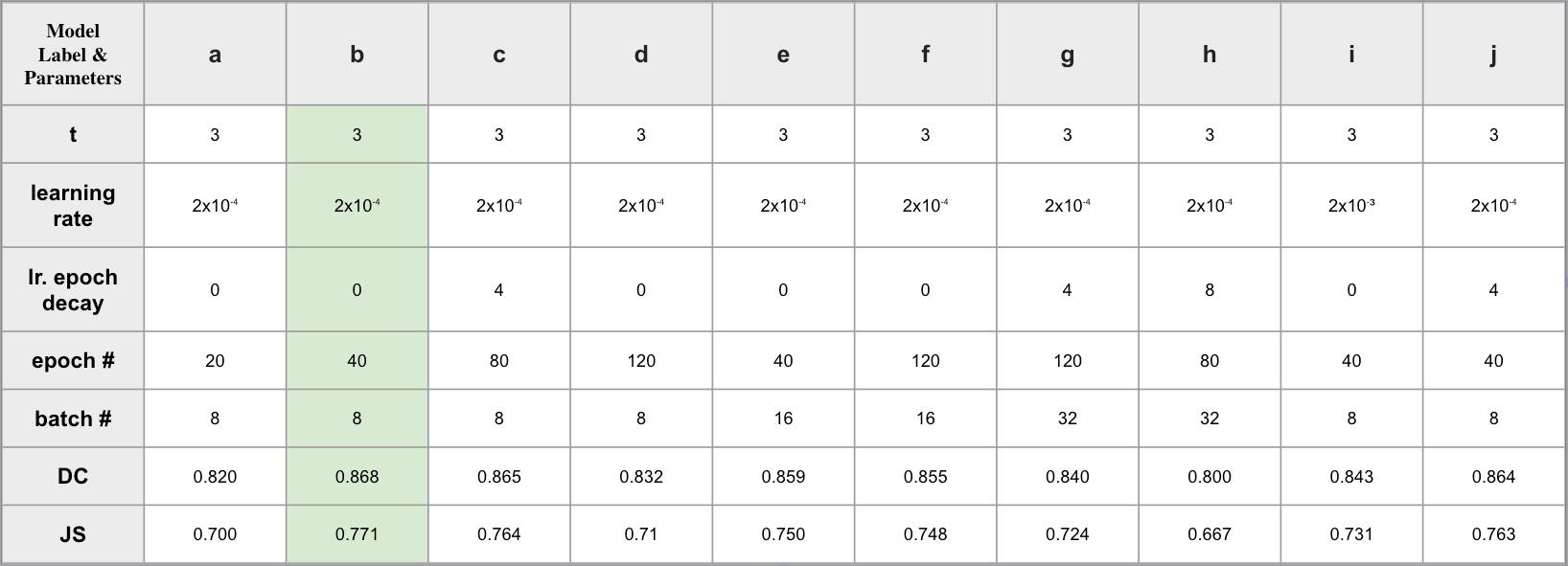
Table 4: Experimets for the R2U-Net Large.
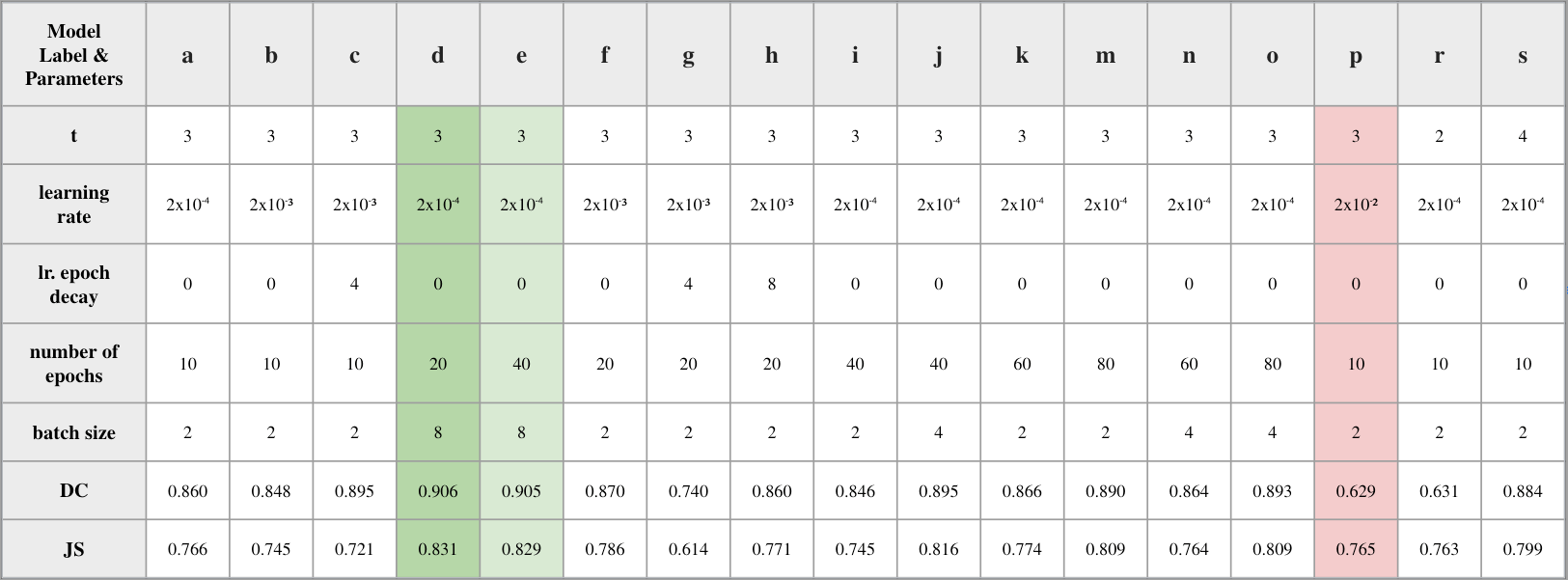
The outcomes using the determined optimal setting, namely model d in Table 4, are provided in Figures 5 and 6. The former figure demonstrates the samples that the model was successful in separating the foreground from the background. In other words, separating the cats and dogs from the background. The segmented results and the ground truth images are well-aligned and differ fractionally. Nevertheless, there are cases which the model was not able to output these high-quality results. The images demonstrating these outcomes are provided in Figure 6.

Figure 5: Samples from successful predictions. First row: original images, second row: ground truth, third row: predictions

Figure 6: Samples from inadequate predictions. First row: original images, second row: ground truth, third row: predictions
We implemented our R2U-Net model on the Oxford-IIIT Pet Dataset and compared it against various baseline models built on the UNet architecture. Specifically, we trained and tested models such as UNet, UNet+Inceptionv3, and UNet-ResNet34 on the same dataset. Table 5 presents the comparison results, showing that while our R2U-Net model outperforms the basic UNet model, the UNet+Inceptionv3 and UNet+ResNet34 models achieve better performance than the R2U-Net architecture.
| Models / Metrics | IOU (JS) | DC |
|---|---|---|
| UNet | 0.333 | 0.464 |
| UNet + Inceptionv3 | 0.916 | 0.915 |
| UNet + ResNet34 | 0.910 | 0.951 |
| R2U-Net Large | 0.831 | 0.906 |
Acknowledgement
I would like to extend my gratitude to Erdem Eren Çağlar for his invaluable assistance and support.
References
- O. Ronneberger, P. Fischer, and I. Brox, “U-net: Convolutional networks for biomedical image segmentation.” International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
- M. Z. Alam, M. Hasan, C. Yakopcic, T. M. Taha and V. K. Asari, “Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation”.
- O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. V. Jawahar, ”Cats and Dogs,” in IEEE Conference on Computer Vision and Pattern Recognition, 2012.
- K. Sundarrajan, B. K. Rajendran, D. Balasubramanian, Fusion of ensembled UNET and ensembled FPN for semantic segmentation. Traitement du Signal, Vol. 40, No. 1, pp. 297-307. https://doi.org/10.18280/ts.400129
You might also be interested in reading this: A Cloud-Native Application: GelGit Travel
Hasan Alp Caferoglu © 2024